Multi-Agent Orchestration for Vision Systems (LangChain + AWS)
Shawn Wilborne
August 27, 2025
4
min read
Modern computer-vision workflows often involve multiple specialized agents (image classifiers, annotation tools, QA reviewers, billing trackers) working together. An LLM-based orchestrator can plan and route tasks across these agents, think cognitive orchestration—, where the “master agent” uses context and SOPs to decide the next step. With LangChain routing and LangGraph multi-agent workflows, an image analysis request can be decomposed into subtasks (classification → annotation → review → billing), each handled by an independent service. This yields a decoupled, scalable system and preserves traceability of decisions and data flows. For teams exploring agent platforms, compare LangGraph (stateful orchestration for agents) with OpenAI’s Agents SDK (tool-calling & orchestration primitives) and the evolving Assistants/Responses tooling.
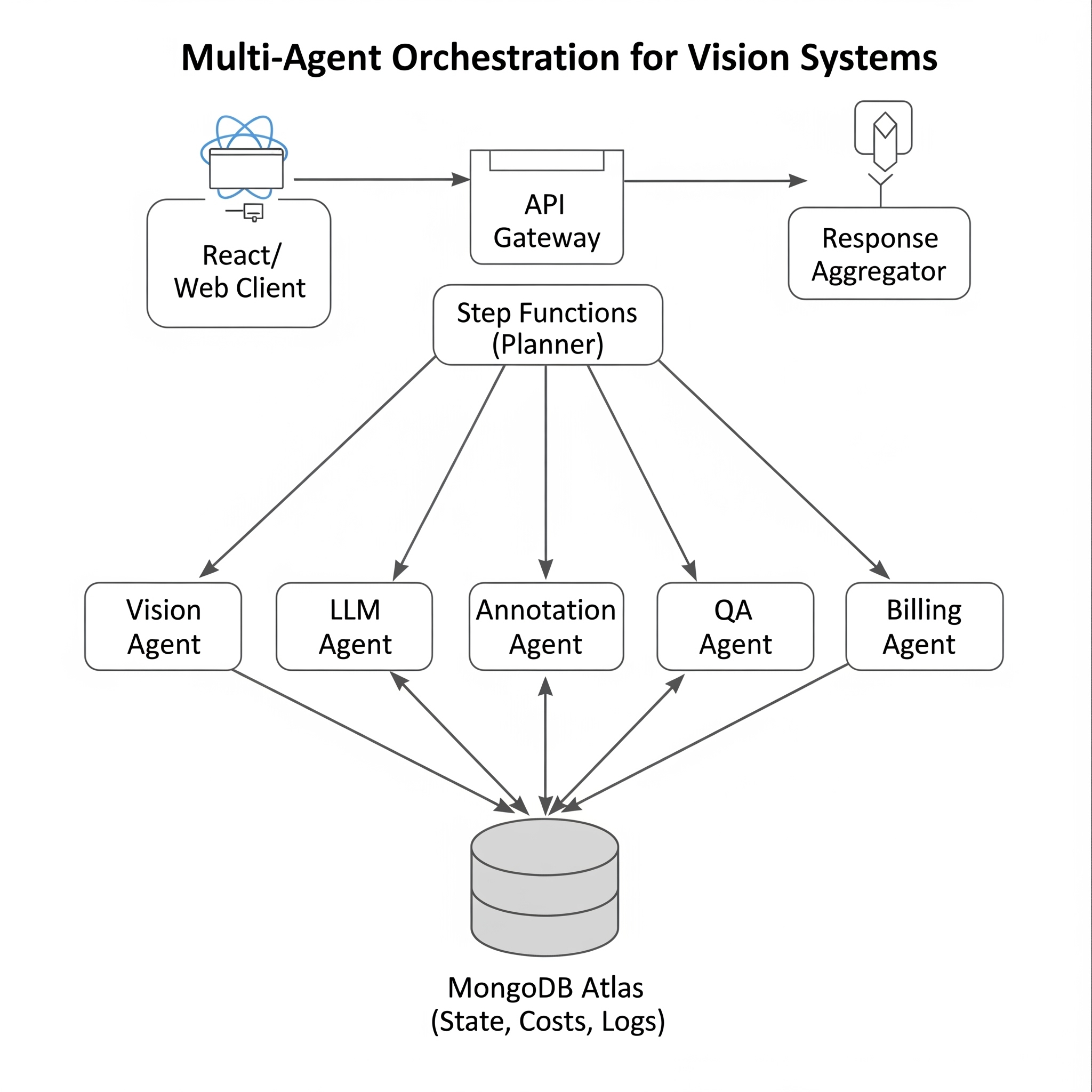
System Diagram
Multi-Agent Orchestration for Vision Systems
Image Overview Boxes: React/Web client → API Gateway → Step Functions (Planner: LangChain/LangGraph) → Parallel branches: (A) Vision Agent (ECS/SageMaker GPU) (B) LLM Agent (Lambda → OpenAI/Claude) (C) Annotation Agent (Lambda/service) (D) QA Agent (LLM; escalate to Human Review queue on low confidence) (E) Billing Agent → MongoDB Atlas (state, costs, logs) → Response aggregator → Client. Callouts: Distributed/Inline Map for large fan-out; Inline map/parallels for small fan-out.
Reference Architecture (AWS + LangChain + Mongo)
Ingress & Orchestrator. Client calls an API Gateway endpoint, which invokes an AWS Step Functions state machine. Choice/Map states implement routing and parallelism. The planner is a LangChain/LangGraph “conductor” deciding which sub-agents to call next (e.g., vision vs. LLM).
Agents as Lambdas/Services. Each agent is a Lambda (for light/CPU work or external API calls) or a containerized service on ECS/Fargate or SageMaker (for GPU inference like YOLO/CLIP).
Shared Memory & Logs.MongoDB Atlas stores agent state, intermediate artifacts, confidence scores, costs, and audit logs for dashboards and billing.
Human-in-the-Loop. If a QA agent’s confidence drops below a threshold, the workflow emits a human review task; otherwise it proceeds autonomously.
Parallelism patterns: For high throughput, use Distributed Map to fan-out per-image tasks at scale. For modest batches, inline Map (parallel state) in Step Functions works well (example).
Usage & Cost:tokens_in/out, gpu_seconds, lambda_gb_seconds, cost_usd per step and totals.
Audit Trail: full trace of decisions for compliance.
Atlas pricing fits startups through enterprise: free tier for prototyping; Flex and Dedicated tiers scale up by RAM/CPU/storage (pricing, Atlas on AWS).
Human-in-the-Loop (HITL) Triggers
Policy: If confidence < 0.9 or class in {rare, regulated}, add a Review task.
Routing: Planner writes a “needs_review” flag in Mongo; Step Functions routes to a human review queue/service.
Closure: Reviewer decision updates Mongo; the workflow resumes. This preserves automation speed while keeping quality and compliance.
Costs You Can Explain to Stakeholders
Step Functions: $0.025 per 1,000 state transitions (Standard) — simple to estimate by counting steps (official pricing; costing blog).
Lambda: $0.20 per 1M requests + compute billed per GB-second (pricing; a handy back-of-napkin rate is ~$0.00001667/GB-s; see also calculator explainer).
Fargate: Pay-as-you-go for vCPU-seconds and GB-seconds (pricing; background explainer here).
MongoDB Atlas: free tier for dev; Flex/Dedicated tiers scale up as needed (pricing).
Rule of thumb (example): 1,000 images, 5 workflow steps each → ~5,000 Step Functions transitions ≈ $0.125; light Lambda work adds a few cents; MongoDB is a fixed monthly line item for small workloads. GPU endpoints dominate cost when you keep them warm; use Fargate jobs or batch endpoints for spiky loads.
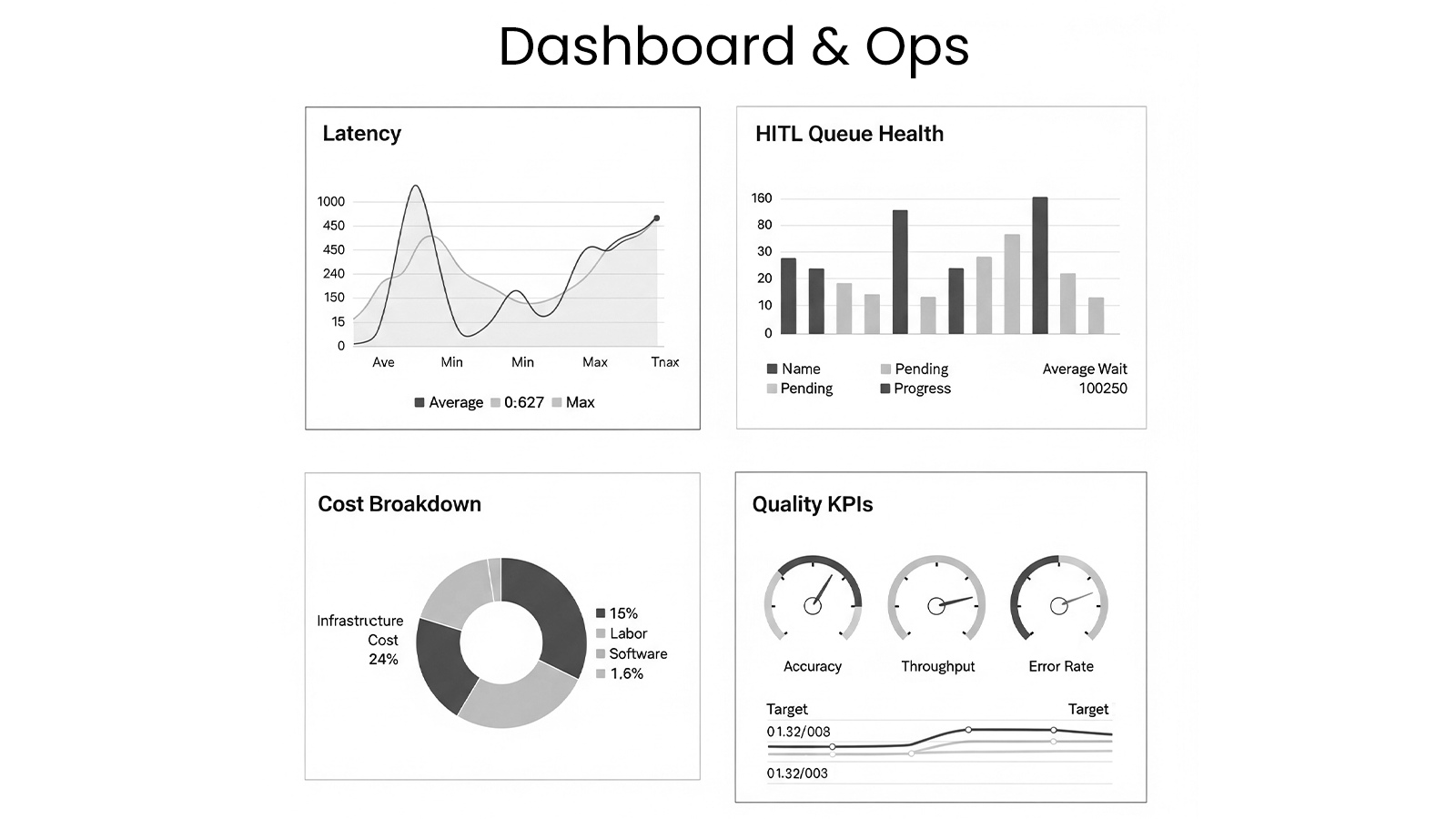
Dashboard & Ops (what to show your PM/CTO)
Latency percentiles per agent (LLM vs GPU vs Lambda).
Cost breakdown by step/model/backend (tokens, GPU seconds, Lambda GB-seconds).
HITL queue health (backlog, average review time).
Quality KPIs (auto-accept rate, defect rate by class, drift alarms).
When to Choose What
All-serverless (Lambda + Step Functions): best for glue logic, light preprocessing, and LLM API calls where you don’t need GPUs and you value minimal ops.
GPU services (Fargate/SageMaker): best for heavy vision inference (YOLO/CLIP) or when you need warm models & low p95 latency.
LangGraph vs vendor SDKs: choose LangGraph for graph-based, stateful multi-agent flows and deep integration with LangChain tools; consider OpenAI’s Agents SDK if your stack is already centered on OpenAI models and you want their native tools and tracing.
.svg)
.png)





.svg)